

在这个时代没有人可以忽略 k8s 今天开始搭建 k8s 的基座,后续也会试试在 k8s 的基础上能不能玩出其他花样
这次准备了一共三台 ubuntu 一台 master 两台 worker ,都是基于在 pve 虚拟平台上来进行搭建的,一切准备就绪过后,就准备开始吧
1.重置 ID
ID 指的是 Machine-ID 是 Linux 系统的全局唯一标识符,在 pve 上通过克隆得到了三台一样的 ubuntu 系统的机器,但是因为是克隆所以这三台机器的 Machine-ID 是一样的,而在 k8s 中 CNI 插件是通过 Machine-ID 来区分不同的节点的,ID 一致只会被 k8s 认为是一个节点,造成路由表的混乱,变成黑洞,Pod跨界点通信失败。
#删除系统生成的 ID 避免出现一致
sudo rm -f /etc/machine-id /var/lib/dbus/machine-id
#生成一个全新的 ID
sudo dbus-uuidgen --ensure=/etc/machine-id
#文件初始化
sudo dbus-uuidgen --ensure
#查看 ID 确保没有 ID 不一致
cat /etc/machine-id2.主机名 && Hosts 映射
主机名的设置其实和 Machine-ID 的原理是差不多的,防止 k8s 集群认为重复的主机名是为同一个节点,避免后期的报错
而 /etc/hosts 的静态映射是为了让所有的 node 可以通过主机名就可以解析到相对应的 IP 地址,不用去依赖 Dns 服务,为的就是防止 DNS 出现问题,导致整个集群调度出现问题引发的瘫痪。
#在 Master 上设置
sudo hostnamectl set-hostname master-01
#在worker-01 上设置
sudo hostnamectl set-hostname worker-01
#在worker-02 上设置
sudo hostnamectl set-hostname worker-02配置静态的 Hosts 映射,每个节点都需要操作一次
#配置相对应的静态映射
cat <<EOF | sudo tee -a /etc/hosts
IP master-01
IP worker-01
IP worker-02
EOF全部完成了过后就可以进行简单的验证 Ping 一下主机名就可以


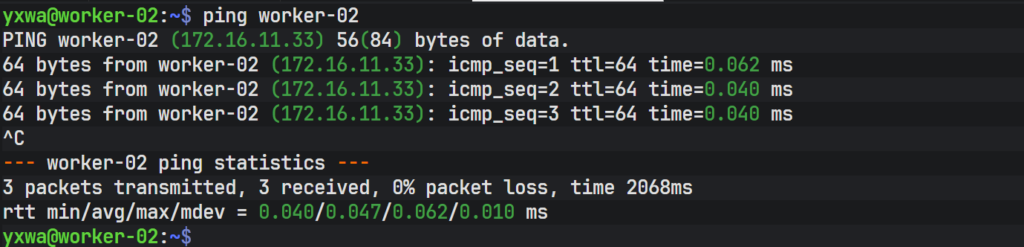
验证过后发现都是可以通过 Hostname 来解析
3.关闭 Swap
kubernetes 要求关闭 Swap 的主要原因是为了保证资源管理的确定性、性能、稳定性
Swap 的关闭是需要在所有的节点上执行的,需注意
#在所有节点上执行
sudo swapoff -a
#永久性关闭Swap,直接注释掉 Swap 行,防止重启过后恢复
sudo sed -i '/swap/s/^/#/' /etc/fstab4.加载内核模块 && 设置网络参数
Overlay
Kubernetes 容器运行时,需要 Overlay 来高效管理容器镜像层和容器可写层,没有 Overlay ,容器无法正常启动和运行
br_netfilter
让 Linux 桥接流量能够通过 Netfilter 规则,默认的情况下桥接的流量会绕过,会导致网络策略,Service转发等失效
#申明在系统启动的时候使用自动加载的内核模块
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
#加载 Overlay 与 br_netfilter 模块
sudo modprobe overlay
sudo modprobe br_netfilter配置网络参数
#设置网络参数
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
#生效一下配置
sudo sysctl --system4. Containerd
K8s 在1.24版本之前是支持原生的 Docker 那个时候的想要启动 Docker 启动容器,具体流程大概是这样
Kubelet → dockershim → dockerd → containerd → runc → 容器进程
dockershim是 K8s 为了兼容 Docker 而写的一个临时适配器
dockerd是 Docker 的守护进程,功能繁多
这个启动容易的过程中,dickershim和dockerd这两层是可以省略的,减少进程数并且可以减少在启动过程中报错的问题
在意识到这个问题之后,K8s 在1.24版本过后开始使用 Containerd ,流程就变成了这样
Kubelet → containerd → runc → 容器进程
这样的改动可以让 K8s 性能更好,故障点减少
#所有节点安装 Containerd 和依赖
sudo apt-get update
sudo apt-get install -y containerd apt-transport-https ca-certificates curl gpg
#生成默认的配置文件
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml > /dev/null
#启用 SystemdCgroup
sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
#替换 sandbox 镜像为阿里云源
sudo sed -i "s|registry.k8s.io/pause|registry.aliyuncs.com/google_containers/pause|g" /etc/containerd/config.toml
# 重启 containerd 并设置开机自启
sudo systemctl restart containerd
sudo systemctl enable containerd验证
#验证 containerd 是否正常运行
sudo systemctl status containerd
#验证 Systemdcgroup 是否开启
grep "SystemdCgroup" /etc/containerd/config.toml
#验证是否已经更换为阿里云源
containerd config dump | grep sandbox

5. Kubeadm / kubelet / kubectl
Kubeadm 集群的安装器和升级器,不负责实际运行业务pod
kubelet 每个节点的管家,负责在本节点上管理 pod 和容器
kubectl 用户的遥控器,用于与集群交互

为了方便理解 可以这样理解
用 kubeadm 搭建集群
靠 kubelet 驱动每个节点
用 kubectl 来指挥整个集群
#所有的节点都需要一下操作
#导入阿里云的 Kubernetes 仓库的 GPG 密钥
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/deb/Release.key \
| sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
#添加阿里云的 Kubernetes 仓库
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/deb/ /" \
| sudo tee /etc/apt/sources.list.d/kubernetes.list
#安装三大组件
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
#锁定一下版本,防止系统自动升级可能会导致的不兼容问题
sudo apt-mark hold kubelet kubeadm kubectl
#第一次启动 Kubelet
sudo systemctl enable --now kubelet
#验证
kubeadm version
kubelet --version
kubectl version --client在 Master-01上

在 Worker-01上

在 Worker-02上

6.初始化 && 运行 K8s
首先是要对 Master-01进行初始化,让后续的节点可以加入集群,生成证书和配置文件等
sudo kubeadm init \
--pod-network-cidr=10.244.0.0/16 \
--image-repository=registry.aliyuncs.com/google_containers \
--kubernetes-version=v1.30.14pod-network-cidr=10.244.0.0/16 这是 pod 网络的 IP 地址(默认)
image-repository=registry.aliyuncs.com/google_containers 指定为阿里云镜像源
kubernetes-version=v1.30.14 指定版本
在完成上述步骤过后,需要特别注意 Token 与 Hash ,后续加入集群时需要用到

接下来需要配置 Kubectl 命令需要读取 Kubeconfig 文件来活的 API Server 的地址和认证凭据
#需在 Master 上配置
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
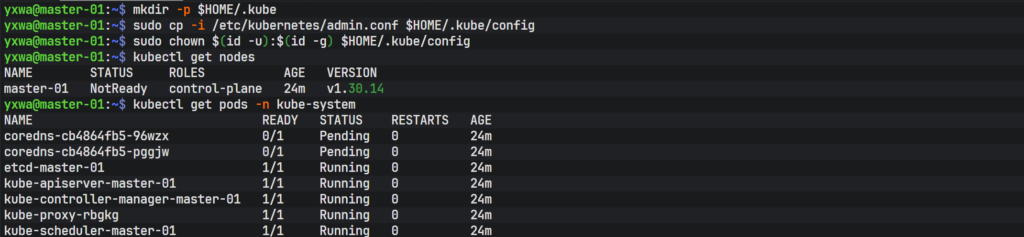
#验证且查看当前节点
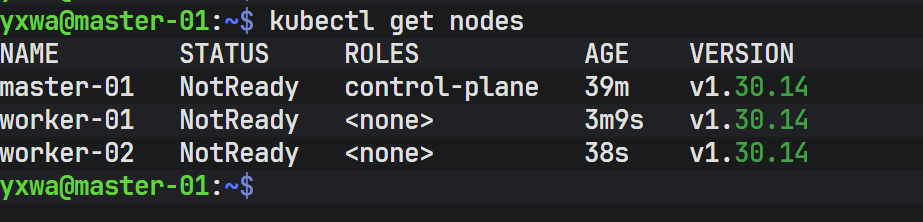
kubectl get nodes
#在没有部署网络插件之前 状态都为 Notread
#查看 Pod 状态
kubectl get pods -n kube-system在 Master-01上
7.加入集群
前面已经提到过需要注意的 Token 和 Hash 在这里需要用上 我们需要用这两个值,来加入到已经创建好的集群里面
需要注意的是 Token 是有有效期的,如果超过24小时了,就需要在重新申请一个
#重新申请 Token
sudo kubeadm token create --print-join-command
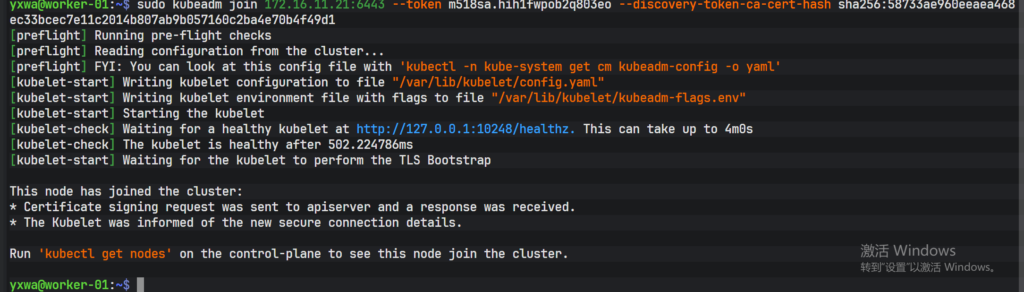
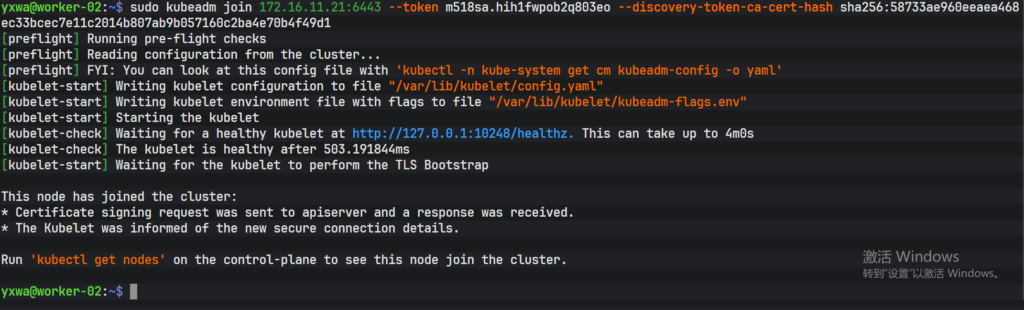
#在所有的 Worker 上执行
udo kubeadm join <master_IP:6443>\
--token <token值> \
--discovery-token-ca-cert-hash sha256:<hash值>在 Worker-01上
这里的 IP 为 Master-01 的 IP 端口一般为6443
在 Worker-02上
在 Master-01上,可以看到已经成功加入了进来
8.网络插件
Kubernetes 对于集群的网络是有着三个硬性要求的:
Pod→to→pod 每个 Pod 都拥有真实 IP ,不同节点上的 Pod 可以通过 IP 直接互相访问
Pod→to→service Pod 可以通过 Service 的 ClusterIP 或者 DNS 名称访问后端 Pod
External→to→service 外部客户端可通过 NodePort、LoadBalancer 或 Ingress 访问集群内的 Service。
Flannel-学习小型环境 ⭐
Flannel 默认是使用 Vxlan在节点间构建一个叠加的网络,每个节点会被分配一个子网,Pod发出的数据包先通过 Vxlan 隧道封装,到达目标节点后解封

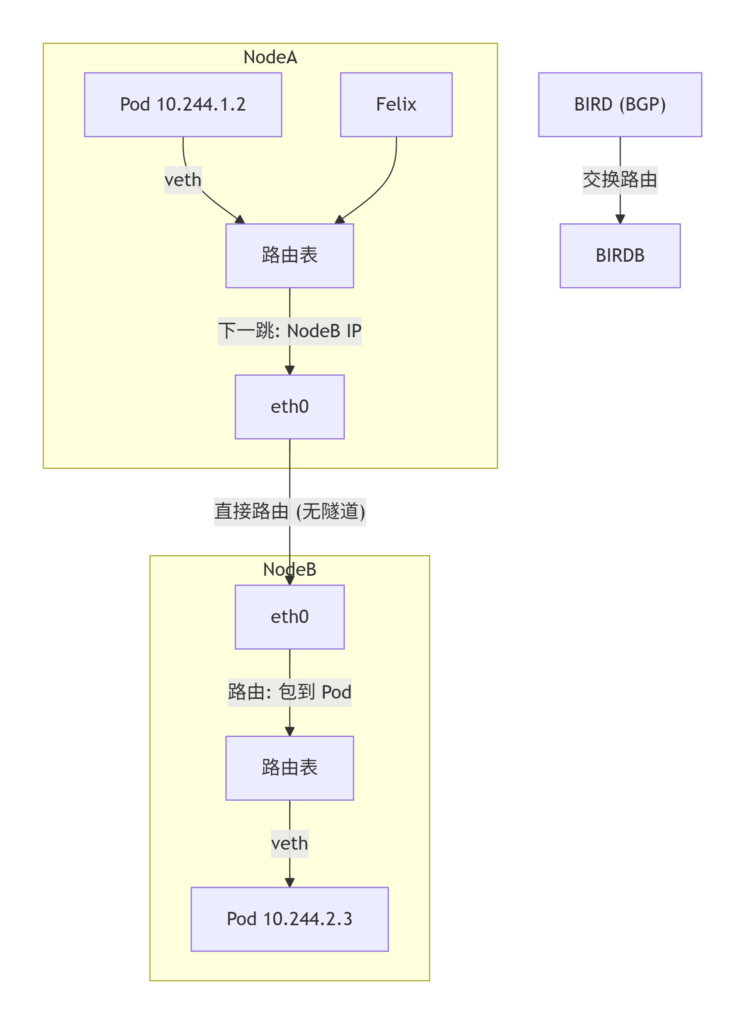
Calico-生产首选 ⭐⭐
Calico 是采用的三层路由,每个节点的 Pod 子网通过 BGP 广播到其他节点,节点路由器或 BGP 客户端负责转发
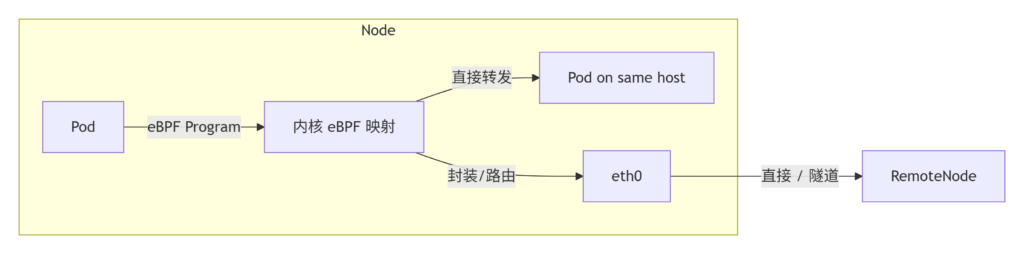
Cilium-高性能 ⭐⭐⭐
Cilium 是利用 Linux 内核的 eBPF 技术,在 socket 层或网卡驱动层直接处理数据包,能实现极强的性能,但是对内核版本要求较高≥5.1,配置复杂
这里我们选择的是生产环境中用的最多的 Calico ,Calico 在每个节点上都会运行以下组件,来保证网络
Felie 每个节点上的大脑,编程路由和 Iptables 规则
Bird BGP客户端,把节点上 Pod 网段宣告给其他节点
Calico-node 以 DaemonSet 方式运行在每个节点上的 Pod,包含 Felix 和 BIRD
calico-kube-controllers 监听 K8s API 中的 NetworkPolicy 变更,并同步到 Calico
#下载 Cailco.yaml
curl -O https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/calico.yaml
#启用环境变量
sed -i 's|# - name: CALICO_IPV4POOL_CIDR|- name: CALICO_IPV4POOL_CIDR|' calico.yaml
# Calico 的默认网段为192.168.0.0,修改为 kubeadm init 所指定的10.244.0.0
sed -i 's|# value: "192.168.0.0/16"| value: "10.244.0.0/16"|' calico.yaml
#替换国内镜像源
sed -i 's|docker.io|docker.m.daocloud.io|g' calico.yaml
#部署
kubectl apply -f calico.yaml
#等待 Calico 部署
kubectl get pods -n kube-system -l k8s-app=calico-node -w
#查看节点状态(ready)
kubectl get nodes在 Master-01上

恭喜你也恭喜我 我们都一起完成了 K8s 的基础部署,现在可以继续在上面去做你想做的事,加油吧!
Comments | NOTHING